目录
golang 内存和调度
Tags: Golang
Published: 2024年6月19日
概要: The blog discusses the memory and scheduling aspects of the Go programming language.
1 GMP
1.1 Goroutine调度器的GMP模型的设计思想
1.1.1 GMP模型

Processor,它包含了运行 goroutine 的资源,如果线程想运行 goroutine,必须先获取 P,P 中还包含了可运行的 G 队列。
在 Go 中,线程是运行 goroutine 的实体,调度器的功能是把可运行的 goroutine 分配到工作线程上。

全局队列(Global Queue):存放等待运行的 G。 P 的本地队列:同全局队列类似,存放的也是等待运行的 G,存的数量有限,不超过 256 个。新建 G’时,G’优先加入到 P 的本地队列,如果队列满了,则会把本地队列中一半的 G 移动到全局队列。 P 列表:所有的 P 都在程序启动时创建,并保存在数组中,最多有 GOMAXPROCS(可配置) 个。 M:线程想运行任务就得获取 P,从 P 的本地队列获取 G,P 队列为空时,M 也会尝试从全局队列拿一批 G 放到 P 的本地队列,或从其他 P 的本地队列偷一半放到自己 P 的本地队列。M 运行 G,G 执行之后,M 会从 P 获取下一个 G,不断重复下去。
Goroutine 调度器和 OS 调度器是通过 M 结合起来的,每个 M 都代表了 1 个内核线程,OS 调度器负责把内核线程分配到 CPU 的核上执行。
有关 P 和 M 的个数问题
1、P 的数量:
由启动时环境变量 GOMAXPROCS 个 goroutine 在同时运行。
2、M 的数量:
go 语言本身的限制:go 程序启动时,会设置 M 的最大数量,默认 10000. 但是内核很难支持这么多的线程数,所以这个限制可以忽略。 runtime/debug 中的 SetMaxThreads 函数,设置 M 的最大数量 一个 M 阻塞了,会创建新的 M。 M 与 P 的数量没有绝对关系,一个 M 阻塞,P 就会去创建或者切换另一个 M,所以,即使 P 的默认数量是 1,也有可能会创建很多个 M 出来。
P和M何时创建
1、P 何时创建:在确定了 P 的最大数量 n 后,运行时系统会根据这个数量创建 n 个 P。
2、M 何时创建:没有足够的 M 来关联 P 并运行其中的可运行的 G。比如所有的 M 此时都阻塞住了,而 P 中还有很多就绪任务,就会去寻找空闲的 M,而没有空闲的,就会去创建新的 M。
1.1.2 调度器的设计策略
复用线程:避免频繁的创建、销毁线程,而是对线程的复用。
1)work stealing 机制
当本线程无可运行的 G 时,尝试从其他线程绑定的 P 偷取 G,而不是销毁线程。
2)hand off 机制
当本线程因为 G 进行系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的线程执行。
利用并行:GOMAXPROCS 设置 P 的数量,最多有 GOMAXPROCS 个线程分布在多个 CPU 上同时运行。GOMAXPROCS 也限制了并发的程度,比如 GOMAXPROCS = 核数/2,则最多利用了一半的 CPU 核进行并行。
抢占:在 coroutine 中要等待一个协程主动让出 CPU 才执行下一个协程,在 Go 中,一个 goroutine 最多占用 CPU 10ms,防止其他 goroutine 被饿死,这就是 goroutine 不同于 coroutine 的一个地方。
全局 G 队列:在新的调度器中依然有全局 G 队列,但功能已经被弱化了,当 M 执行 work stealing 从其他 P 偷不到 G 时,它可以从全局 G 队列获取 G。
1.1.3 go func()调度流程

从上图我们可以分析出几个结论:
1、我们通过 go func () 来创建一个 goroutine;
2、有两个存储 G 的队列,一个是局部调度器 P 的本地队列、一个是全局 G 队列。新创建的 G 会先保存在 P 的本地队列中,如果 P 的本地队列已经满了就会保存在全局的队列中;
3、G 只能运行在 M 中,一个 M 必须持有一个 P,M 与 P 是 1:1 的关系。M 会从 P 的本地队列弹出一个可执行状态的 G 来执行,如果 P 的本地队列为空,就会向其他的 MP 组合偷取一个可执行的 G 来执行;
4、一个 M 调度 G 执行的过程是一个循环机制;
5、当 M 执行某一个 G 时候如果发生了 syscall 或则其余阻塞操作,M 会阻塞,如果当前有一些 G 在执行,runtime 会把这个线程 M 从 P 中摘除 (detach),然后再创建一个新的操作系统的线程 (如果有空闲的线程可用就复用空闲线程) 来服务于这个 P;
6、当 M 系统调用结束时候,这个 G 会尝试获取一个空闲的 P 执行,并放入到这个 P 的本地队列。如果获取不到 P,那么这个线程 M 变成休眠状态, 加入到空闲线程中,然后这个 G 会被放入全局队列中。
1.1.4 调度器的生命周期

特殊的 M0 和 G0
M0
M0 是启动程序后的编号为 0 的主线程,这个 M 对应的实例会在全局变量 runtime.m0 中,不需要在 heap 上分配,M0 负责执行初始化操作和启动第一个 G, 在之后 M0 就和其他的 M 一样了。
G0
G0 是每次启动一个 M 都会第一个创建的 goroutine,G0 仅用于负责调度的 G,G0 不指向任何可执行的函数,每个 M 都会有一个自己的 G0。在调度或系统调用时会使用 G0 的栈空间,全局变量的 G0 是 M0 的 G0。
package main import "fmt" func main() { fmt.Println("Hello world") }
接下来我们来针对上面的代码对调度器里面的结构做一个分析。
也会经历如上图所示的过程:
- runtime 创建最初的线程 m0 和 goroutine g0,并把 2 者关联。
- 调度器初始化:初始化 m0、栈、垃圾回收,以及创建和初始化由 GOMAXPROCS 个 P 构成的 P 列表。
- 示例代码中的 main 函数是 main.main,runtime 中也有 1 个 main 函数 ——runtime.main,代码经过编译后,runtime.main 会调用 main.main,程序启动时会为 runtime.main 创建 goroutine,称它为 main goroutine 吧,然后把 main goroutine 加入到 P 的本地队列。
- 启动 m0,m0 已经绑定了 P,会从 P 的本地队列获取 G,获取到 main goroutine。
- G 拥有栈,M 根据 G 中的栈信息和调度信息设置运行环境
- M 运行 G
- G 退出,再次回到 M 获取可运行的 G,这样重复下去,直到 main.main 退出,runtime.main 执行 Defer 和 Panic 处理,或调用 runtime.exit 退出程序。
调度器的生命周期几乎占满了一个 Go 程序的一生,runtime.main 的 goroutine 执行之前都是为调度器做准备工作,runtime.main 的 goroutine 运行,才是调度器的真正开始,直到 runtime.main 结束而结束。
1.2 Go调度器调度场景过程全解析
1.2.1 场景1
P 拥有 G1,M1 获取 P 后开始运行 G1,G1 使用 go func() 创建了 G2,为了局部性 G2 优先加入到 P1 的本地队列。

1.2.2 场景2
G1 运行完成后 (函数:goexit),M 上运行的 goroutine 切换为 G0,G0 负责调度时协程的切换(函数:schedule)。从 P 的本地队列取 G2,从 G0 切换到 G2,并开始运行 G2 (函数:execute)。实现了线程 M1 的复用。

1.2.3 场景3
假设每个 P 的本地队列只能存 3 个 G。G2 要创建了 6 个 G,前 3 个 G(G3, G4, G5)已经加入 p1 的本地队列,p1 本地队列满了。

1.2.4 场景4
G2 在创建 G7 的时候,发现 P1 的本地队列已满,需要执行负载均衡 (把 P1 中本地队列中前一半的 G,还有新创建 G 转移到全局队列)
(实现中并不一定是新的 G,如果 G 是 G2 之后就执行的,会被保存在本地队列,利用某个老的 G 替换新 G 加入全局队列)

这些 G 被转移到全局队列时,会被打乱顺序。所以 G3,G4,G7 被转移到全局队列。
1.2.5 场景5
G2 创建 G8 时,P1 的本地队列未满,所以 G8 会被加入到 P1 的本地队列。

G8 加入到 P1 点本地队列的原因还是因为 P1 此时在与 M1 绑定,而 G2 此时是 M1 在执行。所以 G2 创建的新的 G 会优先放置到自己的 M 绑定的 P 上。
1.2.6 场景6
规定:在创建 G 时,运行的 G 会尝试唤醒其他空闲的 P 和 M 组合去执行。

假定 G2 唤醒了 M2,M2 绑定了 P2,并运行 G0,但 P2 本地队列没有 G,M2 此时为自旋线程**(没有 G 但为运行状态的线程,不断寻找 G)**。
1.2.7 场景 7
M2 尝试从全局队列 (简称 “GQ”) 取一批 G 放到 P2 的本地队列(函数:findrunnable())。M2 从全局队列取的 G 数量符合下面的公式:
n = min(len(GQ)/GOMAXPROCS+1,len(GQ/2))
至少从全局队列取 1 个 g,但每次不要从全局队列移动太多的 g 到 p 本地队列,给其他 p 留点。这是从全局队列到 P 本地队列的负载均衡。

假定我们场景中一共有 4 个 P(GOMAXPROCS 设置为 4,那么我们允许最多就能用 4 个 P 来供 M 使用)。所以 M2 只从能从全局队列取 1 个 G(即 G3)移动 P2 本地队列,然后完成从 G0 到 G3 的切换,运行 G3。
1.2.8 场景 8
假设 G2 一直在 M1 上运行,经过 2 轮后,M2 已经把 G7、G4 从全局队列获取到了 P2 的本地队列并完成运行,全局队列和 P2 的本地队列都空了,如场景 8 图的左半部分。
 全局队列已经没有 G,那 m 就要执行 work stealing (偷取):从其他有 G 的 P 哪里偷取一半 G 过来,放到自己的 P 本地队列。P2 从 P1 的本地队列尾部取一半的 G,本例中一半则只有 1 个 G8,放到 P2 的本地队列并执行。
全局队列已经没有 G,那 m 就要执行 work stealing (偷取):从其他有 G 的 P 哪里偷取一半 G 过来,放到自己的 P 本地队列。P2 从 P1 的本地队列尾部取一半的 G,本例中一半则只有 1 个 G8,放到 P2 的本地队列并执行。
1.2.9 场景 9
G1 本地队列 G5、G6 已经被其他 M 偷走并运行完成,当前 M1 和 M2 分别在运行 G2 和 G8,M3 和 M4 没有 goroutine 可以运行,M3 和 M4 处于自旋状态,它们不断寻找 goroutine。

为什么要让 m3 和 m4 自旋,自旋本质是在运行,线程在运行却没有执行 G,就变成了浪费 CPU. 为什么不销毁现场,来节约 CPU 资源。因为创建和销毁 CPU 也会浪费时间,我们希望当有新 goroutine 创建时,立刻能有 M 运行它,如果销毁再新建就增加了时延,降低了效率。当然也考虑了过多的自旋线程是浪费 CPU,所以系统中最多有 GOMAXPROCS 个自旋的线程 (当前例子中的 GOMAXPROCS=4,所以一共 4 个 P),多余的没事做线程会让他们休眠。
1.2.10 场景 10
假定当前除了 M3 和 M4 为自旋线程,还有 M5 和 M6 为空闲的线程 (没有得到 P 的绑定,注意我们这里最多就只能够存在 4 个 P,所以 P 的数量应该永远是 M>=P, 大部分都是 M 在抢占需要运行的 P),G8 创建了 G9,G8 进行了阻塞的系统调用,M2 和 P2 立即解绑,P2 会执行以下判断:如果 P2 本地队列有 G、全局队列有 G 或有空闲的 M,P2 都会立马唤醒 1 个 M 和它绑定,否则 P2 则会加入到空闲 P 列表,等待 M 来获取可用的 p。本场景中,P2 本地队列有 G9,可以和其他空闲的线程 M5 绑定。

1.2.11 场景 11
G8 创建了 G9,假如 G8 进行了非阻塞系统调用。

M2 和 P2 会解绑,但 M2 会记住 P2,然后 G8 和 M2 进入系统调用状态。当 G8 和 M2 退出系统调用时,会尝试获取 P2,如果无法获取,则获取空闲的 P,如果依然没有,G8 会被记为可运行状态,并加入到全局队列,M2 因为没有 P 的绑定而变成休眠状态 (长时间休眠等待 GC 回收销毁)。
1.3 总结
总结,Go 调度器很轻量也很简单,足以撑起 goroutine 的调度工作,并且让 Go 具有了原生(强大)并发的能力。Go 调度本质是把大量的 goroutine 分配到少量线程上去执行,并利用多核并行,实现更强大的并发。
2 内存分配原理
2.1 基础概念
为了方便自主管理内存,做法便是先向系统申请一块内存,然后将内存切割成小块,通过一定的内存分配算法管理内存。
以64位系统为例,Golang程序启动时会向系统申请的内存如下图所示:

预申请的内存划分为spans、bitmap、arena三部分。其中arena即为所谓的堆区,应用中需要的内存从这里分配。其中spans和bitmap是为了管理arena区而存在的。
arena的大小为512G,为了方便管理把arena区域划分成一个个的page,每个page为8KB,一共有512GB/8KB个页;
spans区域存放span的指针,每个指针对应一个或多个page,所以span区域的大小为(512GB/8KB)*指针大小8byte = 512M
bitmap区域大小也是通过arena计算出来,不过主要用于GC。
2.1.1 span
span是用于管理arena页的关键数据结构,每个span中包含1个或多个连续页,为了满足小对象分配,span中的一页会划分更小的粒度,而对于大对象比如超过页大小,则通过多页实现。
根据对象大小,划分了一系列class,每个class都代表一个固定大小的对象,以及每个span的大小。如下表所示:
// class bytes/obj bytes/span objects waste bytes // 1 8 8192 1024 0 // 2 16 8192 512 0 // 3 32 8192 256 0 // 4 48 8192 170 32 // 5 64 8192 128 0 // 6 80 8192 102 32 // 7 96 8192 85 32 // 8 112 8192 73 16 // 9 128 8192 64 0 // 10 144 8192 56 128 // 11 160 8192 51 32 // 12 176 8192 46 96 // 13 192 8192 42 128 // 14 208 8192 39 80 // 15 224 8192 36 128 // 16 240 8192 34 32 // 17 256 8192 32 0 // 18 288 8192 28 128 // 19 320 8192 25 192 // 20 352 8192 23 96 // 21 384 8192 21 128 // 22 416 8192 19 288 // 23 448 8192 18 128 // 24 480 8192 17 32 // 25 512 8192 16 0 // 26 576 8192 14 128 // 27 640 8192 12 512 // 28 704 8192 11 448 // 29 768 8192 10 512 // 30 896 8192 9 128 // 31 1024 8192 8 0 // 32 1152 8192 7 128 // 33 1280 8192 6 512 // 34 1408 16384 11 896 // 35 1536 8192 5 512 // 36 1792 16384 9 256 // 37 2048 8192 4 0 // 38 2304 16384 7 256 // 39 2688 8192 3 128 // 40 3072 24576 8 0 // 41 3200 16384 5 384 // 42 3456 24576 7 384 // 43 4096 8192 2 0 // 44 4864 24576 5 256 // 45 5376 16384 3 256 // 46 6144 24576 4 0 // 47 6528 32768 5 128 // 48 6784 40960 6 256 // 49 6912 49152 7 768 // 50 8192 8192 1 0 // 51 9472 57344 6 512 // 52 9728 49152 5 512 // 53 10240 40960 4 0 // 54 10880 32768 3 128 // 55 12288 24576 2 0 // 56 13568 40960 3 256 // 57 14336 57344 4 0 // 58 16384 16384 1 0 // 59 18432 73728 4 0 // 60 19072 57344 3 128 // 61 20480 40960 2 0 // 62 21760 65536 3 256 // 63 24576 24576 1 0 // 64 27264 81920 3 128 // 65 28672 57344 2 0 // 66 32768 32768 1 0
上表中每列含义如下:
- class: class ID,每个span结构中都有一个class ID, 表示该span可处理的对象类型
- bytes/obj:该class代表对象的字节数
- bytes/span:每个span占用堆的字节数,也即页数*页大小
- objects: 每个span可分配的对象个数,也即(bytes/spans)/(bytes/obj)
- waste bytes: 每个span产生的内存碎片,也即(bytes/spans)%(bytes/obj)
上表可见最大的对象是32K大小,超过32K大小的由特殊的class表示,该class ID为0,每个class只包含一个对象。
span是内存管理的基本单位,每个span用于管理特定的class对象,根据对象大小,span将一个或多个页拆分成多个块进行管理。
type mspan struct { next *mspan //链表前向指针,用于将span链接起来 prev *mspan //链表前向指针,用于将span链接起来 startAddr uintptr // 起始地址,也即所管理页的地址 npages uintptr // 管理的页数 nelems uintptr // 块个数,也即有多少个块可供分配 allocBits *gcBits //分配位图,每一位代表一个块是否已分配 allocCount uint16 // 已分配块的个数 spanclass spanClass // class表中的class ID elemsize uintptr // class表中的对象大小,也即块大小 }

spanclass为10,参照class表可得出npages=1,nelems=56,elemsize为144。其中startAddr是在span初始化时就指定了某个页的地址。allocBits指向一个位图,每位代表一个块是否被分配,本例中有两个块已经被分配,其allocCount也为2。
next和prev用于将多个span链接起来,这有利于管理多个span,接下来会进行说明。
2.1.2 cache
有了管理内存的基本单位span,还要有个数据结构来管理span,这个数据结构叫mcentral,各线程需要内存时从mcentral管理的span中申请内存,为了避免多线程申请内存时不断地加锁,Golang为每个线程分配了span的缓存,这个缓存即是cache。
type mcache struct { alloc [67*2]*mspan // 按class分组的mspan列表 }
alloc为mspan的指针数组,数组大小为class总数的2倍。数组中每个元素代表了一种class类型的span列表,每种class类型都有两组span列表,第一组列表中所表示的对象中包含了指针,第二组列表中所表示的对象不含有指针,这么做是为了提高GC扫描性能,对于不包含指针的span列表,没必要去扫描。
根据对象是否包含指针,将对象分为noscan和scan两类,其中noscan代表没有指针,而scan则代表有指针,需要GC进行扫描。
mcache和span的对应关系如下图所示:
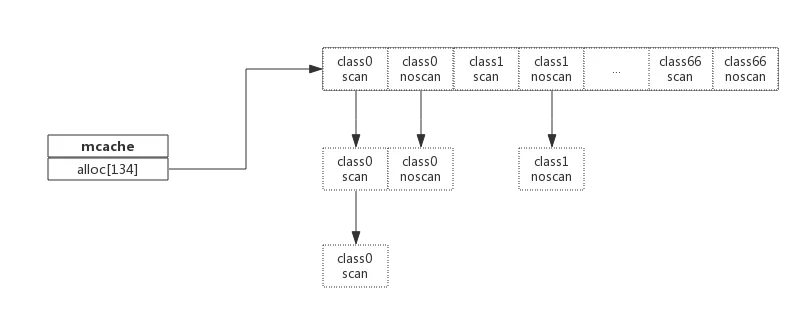
mcache在初始化时是没有任何span的,在使用过程中会动态地从central中获取并缓存下来,根据使用情况,每种class的span个数也不相同。上图所示,class 0的span数比class1的要多,说明本线程中分配的小对象要多一些。
2.1.3 central
cache作为线程的私有资源为单个线程服务,而central则是全局资源,为多个线程服务,当某个线程内存不足时会向central申请,当某个线程释放内存时又会回收进central。
type mcentral struct { lock mutex //互斥锁 spanclass spanClass // span class ID nonempty mSpanList // non-empty 指还有空闲块的span列表 empty mSpanList // 指没有空闲块的span列表 nmalloc uint64 // 已累计分配的对象个数 }
- lock: 线程间互斥锁,防止多线程读写冲突
- spanclass : 每个mcentral管理着一组有相同class的span列表
- nonempty: 指还有内存可用的span列表
- empty: 指没有内存可用的span列表
- nmalloc: 指累计分配的对象个数
线程从central获取span步骤如下:
- 加锁
- 从nonempty列表获取一个可用span,并将其从链表中删除
- 将取出的span放入empty链表
- 将span返回给线程
- 解锁
- 线程将该span缓存进cache
线程将span归还步骤如下:
- 加锁
- 将span从empty列表删除
- 将span加入noneempty列表
- 解锁
2.1.4 heap
从mcentral数据结构可见,每个mcentral对象只管理特定的class规格的span。事实上每种class都会对应一个mcentral,这个mcentral的集合存放于mheap数据结构中。
type mheap struct { lock mutex spans []*mspan bitmap uintptr //指向bitmap首地址,bitmap是从高地址向低地址增长的 arena_start uintptr //指示arena区首地址 arena_used uintptr //指示arena区已使用地址位置 central [67*2]struct { mcentral mcentral pad [sys.CacheLineSize - unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte } }
- lock: 互斥锁
- spans: 指向spans区域,用于映射span和page的关系
- bitmap:bitmap的起始地址
- arena_start: arena区域首地址
- arena_used: 当前arena已使用区域的最大地址
- central: 每种class对应的两个mcentral
从数据结构可见,mheap管理着全部的内存,事实上Golang就是通过一个mheap类型的全局变量进行内存管理的。
mheap内存管理示意图如下:
 系统预分配的内存分为spans、bitmap、arean三个区域,通过mheap管理起来。接下来看内存分配过程。
系统预分配的内存分为spans、bitmap、arean三个区域,通过mheap管理起来。接下来看内存分配过程。
2.2 内存分配过程
针对待分配对象的大小不同有不同的分配逻辑:
-
(0, 16B) 且不包含指针的对象: Tiny分配
-
(0, 16B) 包含指针的对象:正常分配
-
[16B, 32KB] : 正常分配
-
(32KB, -) : 大对象分配
其中Tiny分配和大对象分配都属于内存管理的优化范畴,这里暂时仅关注一般的分配方法。
以申请size为n的内存为例,分配步骤如下:
- 获取当前线程的私有缓存mcache
- 根据size计算出适合的class的ID
- 从mcache的alloc[class]链表中查询可用的span
- 如果mcache没有可用的span则从mcentral申请一个新的span加入mcache中
- 如果mcentral中也没有可用的span则从mheap中申请一个新的span加入mcentral
- 从该span中获取到空闲对象地址并返回
2.3 总结
Golang内存分配是个相当复杂的过程,其中还掺杂了GC的处理,这里仅仅对其关键数据结构进行了说明,了解其原理而又不至于深陷实现细节。
- Golang程序启动时申请一大块内存,并划分成spans、bitmap、arena区域
- arena区域按页划分成一个个小块
- span管理一个或多个页
- mcentral管理多个span供线程申请使用
- mcache作为线程私有资源,资源来源于mcentral
3 垃圾回收(GC)原理
使用三色标记法,另外增加写屏障和删除屏障进行优化以及Go V1.8的混合写屏障机制。具体流程见下面的网址,在此不做赘述
本文作者:AstralDex
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!