目录
分布式理论基础:CAP和BASE
Tags: 分布式
Published: 2024年6月23日
CAP理论
介绍
CAP 理论可以表述为,一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)这三项中的两项。

- 一致性是指“所有节点同时看到相同的数据”,即更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致,等同于所有节点拥有数据的最新版本。
- 可用性是指“任何时候,读写都是成功的”,即服务一直可用,而且是正常响应时间。我们平时会看到一些 IT 公司的对外宣传,比如系统稳定性已经做到 3 个 9、4 个 9,即 99.9%、99.99%,这里的 N 个 9 就是对可用性的一个描述,叫做 SLA,即服务水平协议。比如我们说月度 99.95% 的 SLA,则意味着每个月服务出现故障的时间只能占总时间的 0.05%,如果这个月是 30 天,那么就是 21.6 分钟。
- 分区容忍性具体是指“当部分节点出现消息丢失或者分区故障的时候,分布式系统仍然能够继续运行”,即系统容忍网络出现分区,并且在遇到某节点或网络分区之间网络不可达的情况下,仍然能够对外提供满足一致性和可用性的服务。 在分布式系统中,由于系统的各层拆分,P 是确定的,CAP 的应用模型就是 CP 架构和 AP 架构。分布式系统所关注的,就是在 Partition Tolerance 的前提下,如何实现更好的 A 和更稳定的 C。
CP和AP架构的取舍
在通常的分布式系统中,为了保证数据的高可用,通常会将数据保留多个副本(Replica),网络分区是既成的现实,于是只能在可用性和一致性两者间做出选择。CAP 理论关注的是在绝对情况下,在工程上,可用性和一致性并不是完全对立的,我们关注的往往是如何在保持相对一致性的前提下,提高系统的可用性。 业务上对一致性的要求会直接反映在系统设计中,典型的就是 CP 和 AP 结构。
- CP 架构:对于 CP 来说,放弃可用性,追求一致性和分区容错性。
我们熟悉的 ZooKeeper,就是采用了 CP 一致性,ZooKeeper 是一个分布式的服务框架,主要用来解决分布式集群中应用系统的协调和一致性问题。其核心算法是 Zab,所有设计都是为了一致性。在 CAP 模型中,ZooKeeper 是 CP,这意味着面对网络分区时,为了保持一致性,它是不可用的。关于 Zab 协议,将会在后面的 ZooKeeper 课时中介绍。
- AP 架构:对于 AP 来说,放弃强一致性,追求分区容错性和可用性,这是很多分布式系统设计时的选择,后面的 Base 也是根据 AP 来扩展的。
和 ZooKeeper 相对的是 Eureka,Eureka 是 Spring Cloud 微服务技术栈中的服务发现组件,Eureka 的各个节点都是平等的,几个节点挂掉不影响正常节点的工作,剩余的节点依然可以提供注册和查询服务,只要有一台 Eureka 还在,就能保证注册服务可用,只不过查到的信息可能不是最新的版本,不保证一致性。
BASE理论
介绍
Base 是三个短语的简写,即基本可用(Basically Available)、软状态(Soft State)和最终一致性(Eventually Consistent)。

Base 理论的核心思想是最终一致性,即使无法做到强一致性(Strong Consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual Consistency)。 接下来我们着重对 Base 理论中的三要素进行讲解。
三个要素详解
基本可用
基本可用比较好理解,就是不追求 CAP 中的「任何时候,读写都是成功的」,而是系统能够基本运行,一直提供服务。基本可用强调了分布式系统在出现不可预知故障的时候,允许损失部分可用性,相比正常的系统,可能是响应时间延长,或者是服务被降级。 举个例子,在双十一秒杀活动中,如果抢购人数太多超过了系统的 QPS 峰值,可能会排队或者提示限流,这就是通过合理的手段保护系统的稳定性,保证主要的服务正常,保证基本可用。
软状态
软状态可以对应 ACID 事务中的原子性,在 ACID 的事务中,实现的是强制一致性,要么全做要么不做,所有用户看到的数据一致。其中的原子性(Atomicity)要求多个节点的数据副本都是一致的,强调数据的一致性。 原子性可以理解为一种“硬状态”,软状态则是允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时。
最终一致性
数据不可能一直是软状态,必须在一个时间期限之后达到各个节点的一致性,在期限过后,应当保证所有副本保持数据一致性,也就是达到数据的最终一致性。 在系统设计中,最终一致性实现的时间取决于网络延时、系统负载、不同的存储选型、不同数据复制方案设计等因素。
不同数据一致性模型
一般来说,数据一致性模型可以分为强一致性和弱一致性,强一致性也叫做线性一致性,除此以外,所有其他的一致性都是弱一致性的特殊情况。弱一致性根据不同的业务场景,又可以分解为更细分的模型,不同一致性模型又有不同的应用场景。 在互联网领域的绝大多数场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
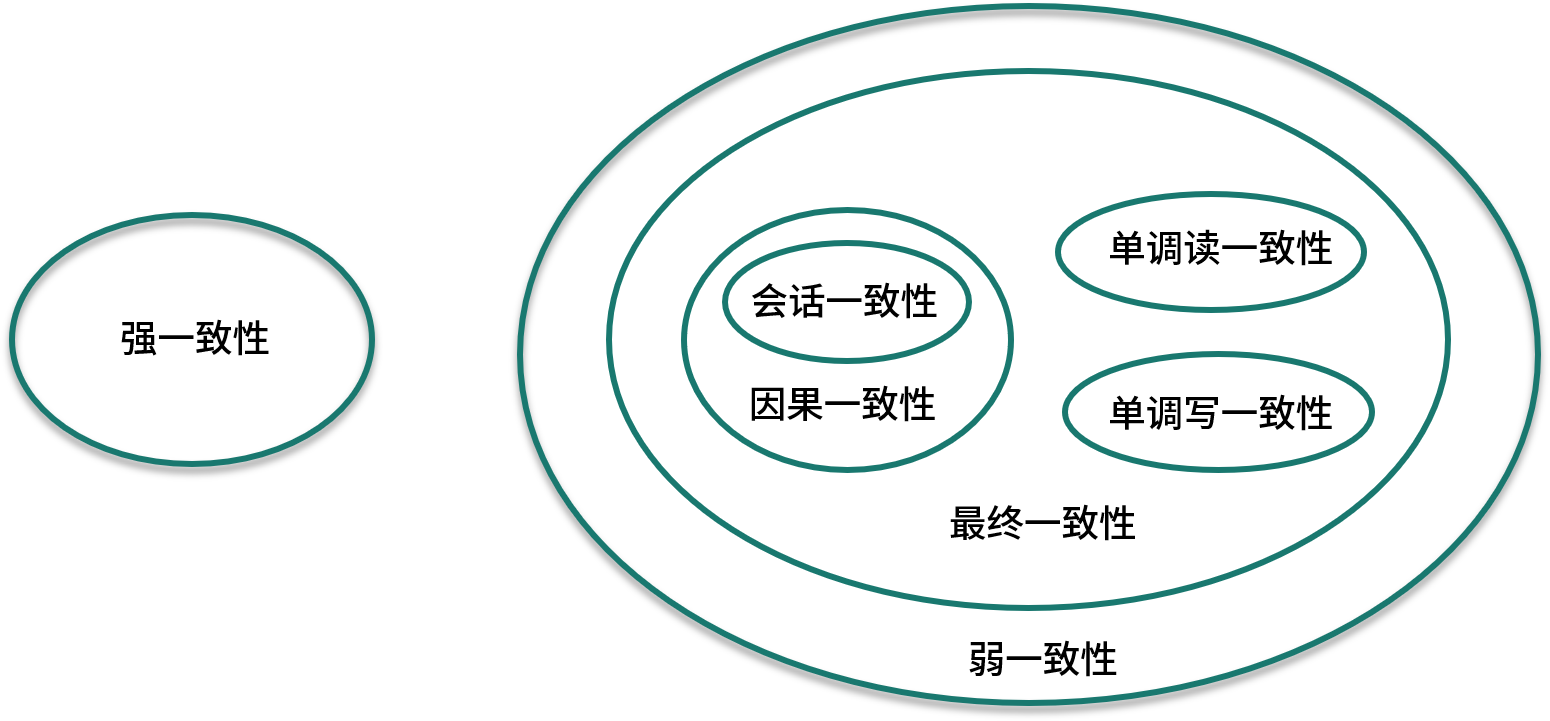
对于一致性,可以分为从服务端和客户端两个不同的视角,上面提到了全局时钟概念,这里关注的主要是外部一致性。
强一致性
当更新操作完成之后,任何多个后续进程的访问都会返回最新的更新过的值,这种是对用户最友好的,就是用户上一次写什么,下一次就保证能读到什么。根据 CAP 理论,这种实现需要牺牲可用性。
弱一致性
系统在数据写入成功之后,不承诺立即可以读到最新写入的值,也不会具体的承诺多久之后可以读到。用户读到某一操作对系统数据的更新需要一段时间,我们称这段时间为“不一致性窗口”。
最终一致性
最终一致性是弱一致性的特例,强调的是所有的数据副本,在经过一段时间的同步之后,最终都能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。 到达最终一致性的时间 ,就是不一致窗口时间,在没有故障发生的前提下,不一致窗口的时间主要受通信延迟,系统负载和复制副本的个数影响。 最终一致性模型根据其提供的不同保证可以划分为更多的模型,包括因果一致性和会话一致性等。
- 因果一致性
因果一致性要求有因果关系的操作顺序得到保证,非因果关系的操作顺序则无所谓。 进程 A 在更新完某个数据项后通知了进程 B,那么进程 B 之后对该数据项的访问都应该能够获取到进程 A 更新后的最新值,并且如果进程 B 要对该数据项进行更新操作的话,务必基于进程 A 更新后的最新值。 因果一致性的应用场景可以举个例子,在微博或者微信进行评论的时候,比如你在朋友圈发了一张照片,朋友给你评论了,而你对朋友的评论进行了回复,这条朋友圈的显示中,你的回复必须在朋友之后,这是一个因果关系,而其他没有因果关系的数据,可以允许不一致。
- 会话一致性
会话一致性将对系统数据的访问过程框定在了一个会话当中,约定了系统能保证在同一个有效的会话中实现“读己之所写”的一致性,就是在你的一次访问中,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。 实际开发中有分布式的 Session 一致性问题,可以认为是会话一致性的一个应用。
本文作者:AstralDex
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!